以前蹭图床,都是考虑自己用服务器写api接口,后来有了 onedrive 的教育版账户以后,发现可以共享目录,而且 onedrive 共享文件企业账户访问速度还挺快,一直想考虑直接用直连共享目录的方式使用calibre书库,可是calibre 的数据全是拼音加英文,完全把文件打乱了,不好检索,要想下载还需要先找到对应目录才行。
前段时间就尝试用 oneindex 作为图床测试应用,但是测试发现 微软的第三方应用访问api 有很多频率限制,不适合做公共图床,自己偶尔用用还行,文件多了不光接口有频次限制,自己建oneindex索引目录也跑不起来。
既然 oneindex 不行,那不如考虑测试直接用office onedrive 自己的共享目录来作为图床使用,稳定,快速,而且访问URL 也是按照目录文件名的方式,有规律可循。
经过改造以后,calibre-web程序服务器只需要放一个 metadata.db 文件,不需要把几百G的图书文件放到服务器,小硬盘也能跑起来几万本图书库索引了。但同样因为本地硬盘并没有图书的文件,只是有个索引,就需要把 calibre-web 程序的在线阅读和发送到 kindle,上传图书的功能都不能使用。只保留基本的图书管理,用户管理,和图书下载功能。
以下是折腾记录:
原理基本就是把图书数据库的目录传到在 onedrive 。
把onedrive目录设置为共享目录,共享目录权限设置为获得链接即可访问。
拿到 onedrive 目录的共享链接保存一下(应该是类似 xxxx-my.sharepoint.com 的你账户组织的域名地址),看看共享链接文件访问的规律。
(基本是先访问一下共享链接,验证到访问权限以后再访问子文件就是目录组装文件的url,共享目录权限的有效期是浏览器关闭前。)
修改 calibre-web/cps/helper.py 文件。
calibre-web 0.6.6 版本 主要是修改图片函数 get_book_cover,改为直接 302 转发到 onedrive 目录下的图片下载地址,网页的 img 标签下载头也可以直接渲染。
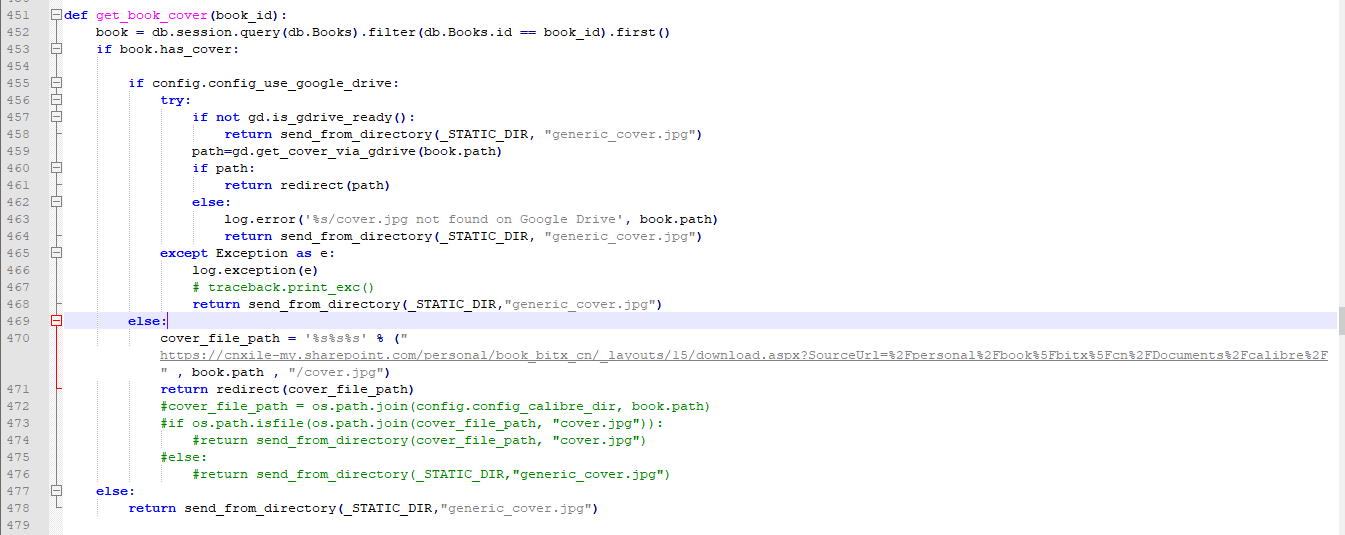
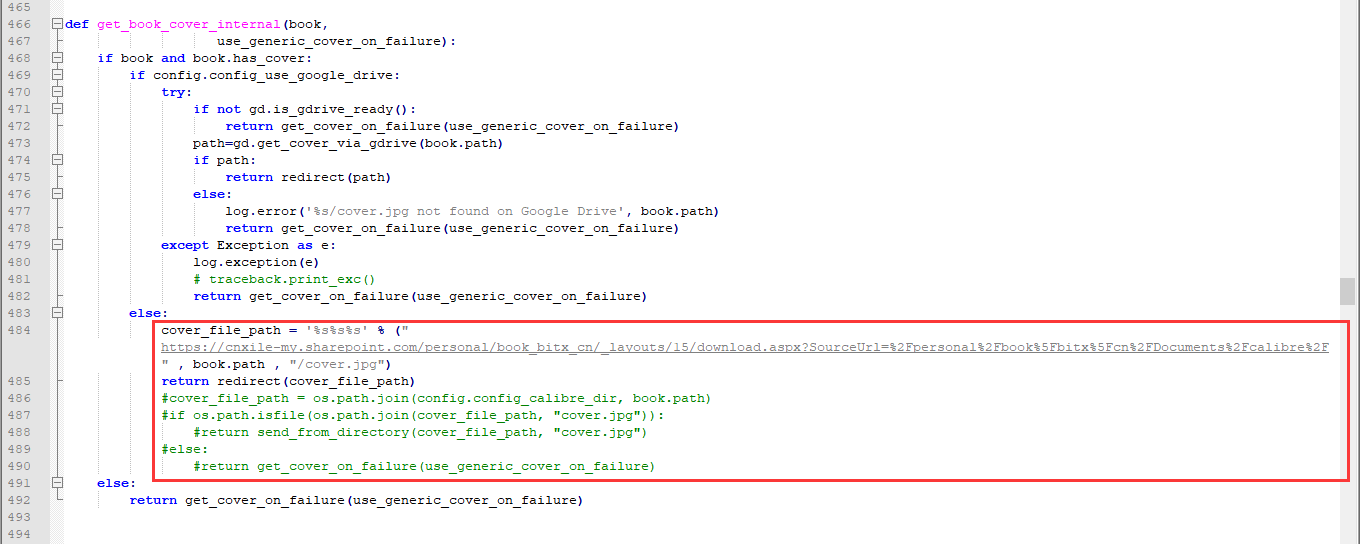
新版本的calibre-web 0.6.7 bate 版本要改get_book_cover_internal 函数。
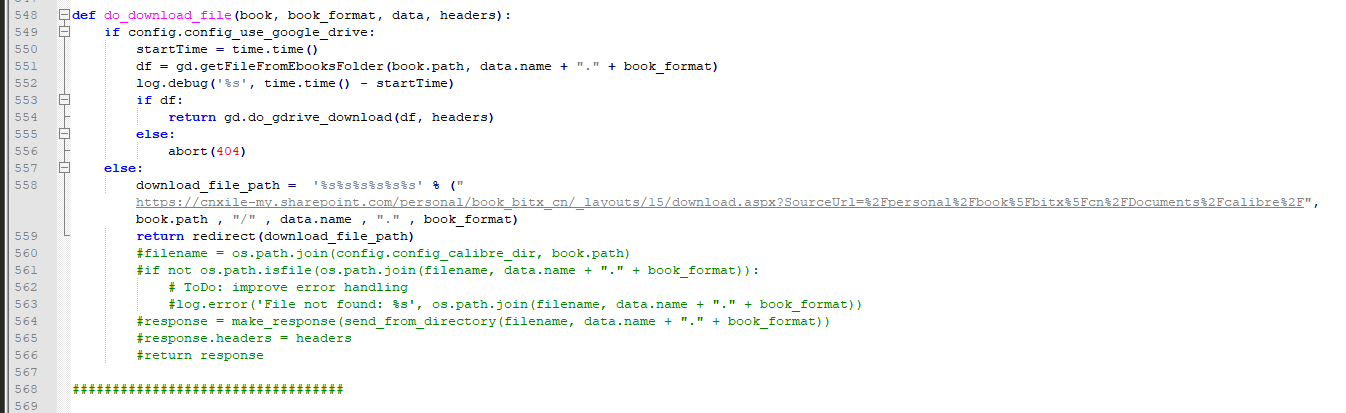
下载函数 do_download_file 也是相同的方式,改成302 跳转到onedrive目录下文件。
因为需要使用共享文件时需要先访问整个目录的共享链接才能获得共享权限。所以需要再写个js或者在页面iframe一下共享目录。
为了防止过多访问共享目录,我写了一个js 用来访问共享目录。
/cps/static/js/shareonedrive.js
代码可以参照:http://www.jialidu.com/static/js/shareonedrive.min.js
为了防止访问代码看到共享地址,特别把代码混淆了一下,可以访问没有min后缀的看源码。
js原理主要时通过记录一个 cookie 来保持与 onedrive 目录同步。关闭浏览器失效。
每次访问前判断有没有访问过共享目录。没有访问过就先请求一次,iframe 或者script模式的共享目录。
然后刷新一下图片,重新加载页面图片即可。
然后编辑:/cps/templates/layout.html
把js放了页面调用里。
把calibre 数据库db 文件上传到服务器calibre-web配置的数据库路径里。
在服务器 可以通过CURL 下载 One Drive 共享盘里的 metadata.db 文件:
curl -# -o test.html “http://www.baidu.com”;
在chrome 浏览器模拟下载 metadata.db 文件,并通过 chrome 调试模式 复制curl地址,使用 Copy all as cURL (bash)功能。
再增加curl -# -o metadata.db 参数:可以只显示进度条不显示文件而下载并重命名文件。
如果不想 calibre 的 metadata.db 数据库文件也被别人下载,那就把共享目录里的 metadata.db 文件删掉,自己共享到另外的位置存储。
重启calibre-web看看效果。
TODO:
1、0.6.6 版本需要继续 改 OPDS 对应 的 下载和图片调用函数。
2、可以继续优化,在模板输出时直接替换图片和文件下载目录,可以减轻服务压力,还可以方便 cdn 加速(改动挺多,不想折腾)。
3、想办法要继续保持在线阅读和发送到 kindle 可用(暂无思路)。
4、给 Vultr 的小内存机器加虚拟内存,要不然 200m 的数据库,512 的内存处理不了,主页会502。
扩展题:
可以考虑如何通过代码截图和公布的源码找到我的共享图书目录。
并使用服务器下载整个目录和数据库。
为啥作者只开放 Google Drive 的功能,没开发 One Drive 的功能呢?
这一系列文章并没有什么具体的技术细节,开了个QQ交流群(72239907),方便大家交流读书、技术问题、图书资源共享。如果有什么软件安装等问题也可以加 calibre 交流群的QQ群(72239907)进行交流。
点击链接加入群聊【爱读书 读好书 calibre】:https://jq.qq.com/?_wv=1027&k=5vYWQsV